structrte_mempool { /* * Note: this field kept the RTE_MEMZONE_NAMESIZE size due to ABI * compatibility requirements, it could be changed to * RTE_MEMPOOL_NAMESIZE next time the ABI changes */ char name[RTE_MEMZONE_NAMESIZE]; /**< Name of mempool. */ RTE_STD_C11 union { void *pool_data; /**< Ring or pool to store objects. */ uint64_t pool_id; /**< External mempool identifier. */ }; void *pool_config; /**< optional args for ops alloc. */ conststructrte_memzone *mz;/**< Memzone where pool is alloc'd. */ int flags; /**< Flags of the mempool. */ int socket_id; /**< Socket id passed at create. */ uint32_t size; /**< Max size of the mempool. */ uint32_t cache_size; /**< Size of per-lcore default local cache. */
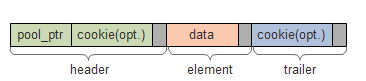
uint32_t elt_size; /**< Size of an element. */ uint32_t header_size; /**< Size of header (before elt). */ uint32_t trailer_size; /**< Size of trailer (after elt). */
unsigned private_data_size; /**< Size of private data. */ /** * Index into rte_mempool_ops_table array of mempool ops * structs, which contain callback function pointers. * We're using an index here rather than pointers to the callbacks * to facilitate any secondary processes that may want to use * this mempool. */ int32_t ops_index;
structrte_mempool_cache *local_cache;/**< Per-lcore local cache */
uint32_t populated_size; /**< Number of populated objects. */ structrte_mempool_objhdr_listelt_list;/**< List of objects in pool */ uint32_t nb_mem_chunks; /**< Number of memory chunks */ structrte_mempool_memhdr_listmem_list;/**< List of memory chunks */
** * A structure that stores a per-core object cache. */ structrte_mempool_cache { unsigned len; /**< Cache len */ /* * Cache is allocated to this size to allow it to overflow in certain * cases to avoid needless emptying of cache. */ void *objs[RTE_MEMPOOL_CACHE_MAX_SIZE * 3]; /**< Cache objects */ } __rte_cache_aligned;
/** * @internal Get several objects from the mempool; used internally. * @param mp * A pointer to the mempool structure. * @param obj_table * A pointer to a table of void * pointers (objects). * @param n * The number of objects to get, must be strictly positive. * @param is_mc * Mono-consumer (0) or multi-consumers (1). * @return * - >=0: Success; number of objects supplied. * - <0: Error; code of ring dequeue function. */ staticinlineint __attribute__((always_inline)) __mempool_get_bulk(struct rte_mempool *mp, void **obj_table, unsigned n, int is_mc) { int ret; structrte_mempool_cache *cache; uint32_t index, len; void **cache_objs; unsigned lcore_id = rte_lcore_id(); uint32_t cache_size = mp->cache_size;
/* cache is not enabled or single consumer */ if (unlikely(cache_size == 0 || is_mc == 0 || n >= cache_size || lcore_id >= RTE_MAX_LCORE)) goto ring_dequeue;
/* Can this be satisfied from the cache? */ if (cache->len < n) { /* No. Backfill the cache first, and then fill from it */ uint32_t req = n + (cache_size - cache->len);
/* How many do we require i.e. number to fill the cache + the request */ ret = rte_ring_mc_dequeue_bulk(mp->ring, &cache->objs[cache->len], req); if (unlikely(ret < 0)) { /* * In the offchance that we are buffer constrained, * where we are not able to allocate cache + n, go to * the ring directly. If that fails, we are truly out of * buffers. */ goto ring_dequeue; }
cache->len += req; }
/* Now fill in the response ... */ for (index = 0, len = cache->len - 1; index < n; ++index, len--, obj_table++) *obj_table = cache_objs[len];
cache->len -= n;
__MEMPOOL_STAT_ADD(mp, get_success, n);
return0;
ring_dequeue:
/* get remaining objects from ring */ if (is_mc) ret = rte_ring_mc_dequeue_bulk(mp->ring, obj_table, n); else ret = rte_ring_sc_dequeue_bulk(mp->ring, obj_table, n);
/** * @internal Put several objects back in the mempool; used internally. * @param mp * A pointer to the mempool structure. * @param obj_table * A pointer to a table of void * pointers (objects). * @param n * The number of objects to store back in the mempool, must be strictly * positive. * @param is_mp * Mono-producer (0) or multi-producers (1). */ staticinlinevoid __attribute__((always_inline)) __mempool_put_bulk(struct rte_mempool *mp, void * const *obj_table, unsigned n, int is_mp) { structrte_mempool_cache *cache; uint32_t index; void **cache_objs; unsigned lcore_id = rte_lcore_id(); uint32_t cache_size = mp->cache_size; uint32_t flushthresh = mp->cache_flushthresh;
/* increment stat now, adding in mempool always success */ __MEMPOOL_STAT_ADD(mp, put, n);
/* cache is not enabled or single producer or non-EAL thread */ if (unlikely(cache_size == 0 || is_mp == 0 || lcore_id >= RTE_MAX_LCORE)) goto ring_enqueue;
/* Go straight to ring if put would overflow mem allocated for cache */ if (unlikely(n > RTE_MEMPOOL_CACHE_MAX_SIZE)) goto ring_enqueue;
/* * The cache follows the following algorithm * 1. Add the objects to the cache * 2. Anything greater than the cache min value (if it crosses the * cache flush threshold) is flushed to the ring. */
/* Add elements back into the cache */ for (index = 0; index < n; ++index, obj_table++) cache_objs[index] = *obj_table;
/* push remaining objects in ring */ if (is_mp) { if (rte_ring_mp_enqueue_bulk(mp->ring, obj_table, n) < 0) rte_panic("cannot put objects in mempool\n"); } else { if (rte_ring_sp_enqueue_bulk(mp->ring, obj_table, n) < 0) rte_panic("cannot put objects in mempool\n"); } }